- Excellent Multilingual Text Rendering: Supports high-precision text generation in multiple languages including English, Chinese, Korean, Japanese, maintaining font details and layout consistency
- Diverse Artistic Styles: From photorealistic scenes to impressionist paintings, from anime aesthetics to minimalist design, fluidly adapting to various creative prompts
- Qwen-Image-DiffSynth-ControlNets/model_patches: Includes canny, depth, and inpaint models
- qwen_image_union_diffsynth_lora.safetensors: Image structure control LoRA supporting canny, depth, pose, lineart, softedge, normal, openpose
- InstantX ControlNet: To be updated
ComfyOrg Qwen-Image live stream
Qwen-Image in ComfyUI - Lightning & LoRAs
Qwen-Image ControlNet in ComfyUI - DiffSynth
Qwen-Image Native Workflow Example
Run on Comfy Cloud There are three different models used in the workflow attached to this document:- Qwen-Image original model fp8_e4m3fn
- 8-step accelerated version: Qwen-Image original model fp8_e4m3fn with lightx2v 8-step LoRA
- Distilled version: Qwen-Image distilled model fp8_e4m3fn
1. Workflow File
After updating ComfyUI, you can find the workflow file in the templates, or drag the workflow below into ComfyUI to load it.
Download Workflow for Qwen-Image Official Model
Distilled versionDownload Workflow for Distilled Model
2. Model Download
Available Models in ComfyUI- Qwen-Image_bf16 (40.9 GB)
- Qwen-Image_fp8 (20.4 GB)
- Distilled versions (non-official, requires only 15 steps)
- The original author of the distilled version recommends using 15 steps with cfg 1.0.
- According to tests, this distilled version also performs well at 10 steps with cfg 1.0. You can choose either euler or res_multistep based on the type of image you want.
3. Workflow Instructions
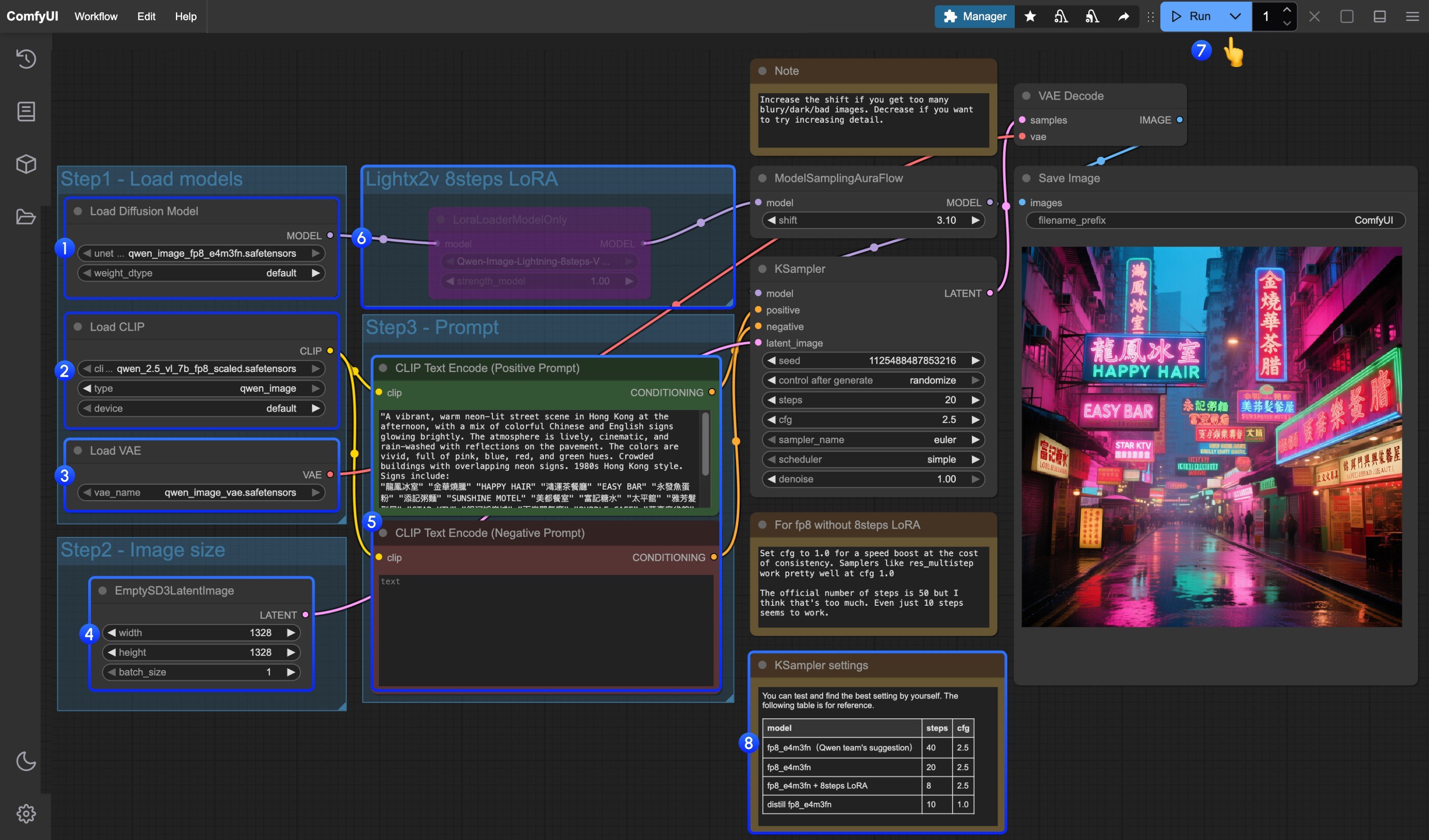
- Make sure the
Load Diffusion Modelnode has loadedqwen_image_fp8_e4m3fn.safetensors - Make sure the
Load CLIPnode has loadedqwen_2.5_vl_7b_fp8_scaled.safetensors - Make sure the
Load VAEnode has loadedqwen_image_vae.safetensors - Make sure the
EmptySD3LatentImagenode is set with the correct image dimensions - Set your prompt in the
CLIP Text Encodernode; currently, it supports at least English, Chinese, Korean, Japanese, Italian, etc. - If you want to enable the 8-step acceleration LoRA by lightx2v, select the node and use
Ctrl + Bto enable it, and modify the Ksampler settings as described in step 8 - Click the
Queuebutton, or use the shortcutCtrl(cmd) + Enterto run the workflow - For different model versions and workflows, adjust the KSampler parameters accordingly
The distilled model and the 8-step acceleration LoRA by lightx2v do not seem to be compatible for simultaneous use. You can experiment with different combinations to verify if they can be used together.
Qwen Image InstantX ControlNet Workflow
This is a ControlNet model, so you can use it as normal ControlNet. Run on Comfy Cloud1. Workflow and Input Images
Download the image below and drag it into ComfyUI to load the workflow
Download JSON Format Workflow
Download the image below as input
2. Model Links
- InstantX Controlnet
ComfyUI/models/controlnet/ folder
- Lotus Depth model
- vae-ft-mse-840000-ema-pruned.safetensors or any SD1.5 VAE
You can also use custom nodes like comfyui_controlnet_aux to generate depth map.
3. Workflow Instructions
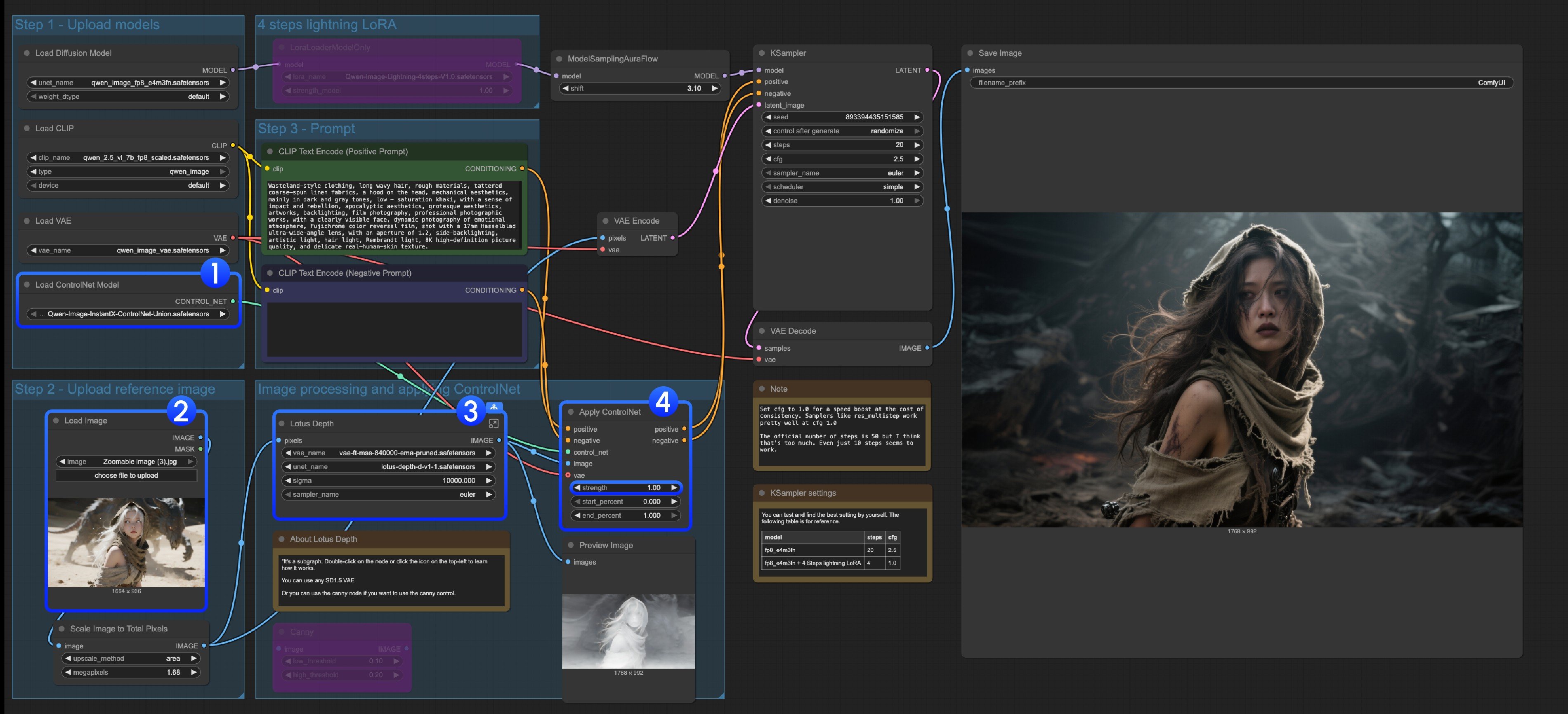
- Ensure that the
Load ControlNet Modelnode correctly loads theQwen-Image-InstantX-ControlNet-Union.safetensorsmodel - Upload input image
- This subgraph uses the Lotus Depth model. You can find it in the templates or edit the subgraph to learn more, make sure all the models are loaded correctly
- Click the
Runbutton, or use the shortcutCtrl(cmd) + Enterto run the workflow
Qwen Image ControlNet DiffSynth-ControlNets Model Patches Workflow
Run on Comfy Cloud This model is actually not a ControlNet, but a Model patch that supports three different control modes: canny, depth, and inpaint. Original model address: DiffSynth-Studio/Qwen-Image ControlNet Comfy Org rehost address: Qwen-Image-DiffSynth-ControlNets/model_patches1. Workflow and Input Images
Download the image below and drag it into ComfyUI to load the corresponding workflow
Download JSON Format Workflow
Download the image below as input:
2. Model Links
Other models are the same as the Qwen-Image basic workflow. You only need to download the models below and save them to theComfyUI/models/model_patches folder
- qwen_image_canny_diffsynth_controlnet.safetensors
- qwen_image_depth_diffsynth_controlnet.safetensors
- qwen_image_inpaint_diffsynth_controlnet.safetensors
3. Workflow Usage Instructions
Currently, diffsynth has three patch models: Canny, Depth, and Inpaint. If you’re using ControlNet-related workflows for the first time, you need to understand that control images need to be preprocessed into supported image formats before they can be used and recognized by the model.
- Canny: Processed canny edge, line art contours
- Depth: Preprocessed depth map showing spatial relationships
- Inpaint: Requires using Mask to mark areas that need to be repainted
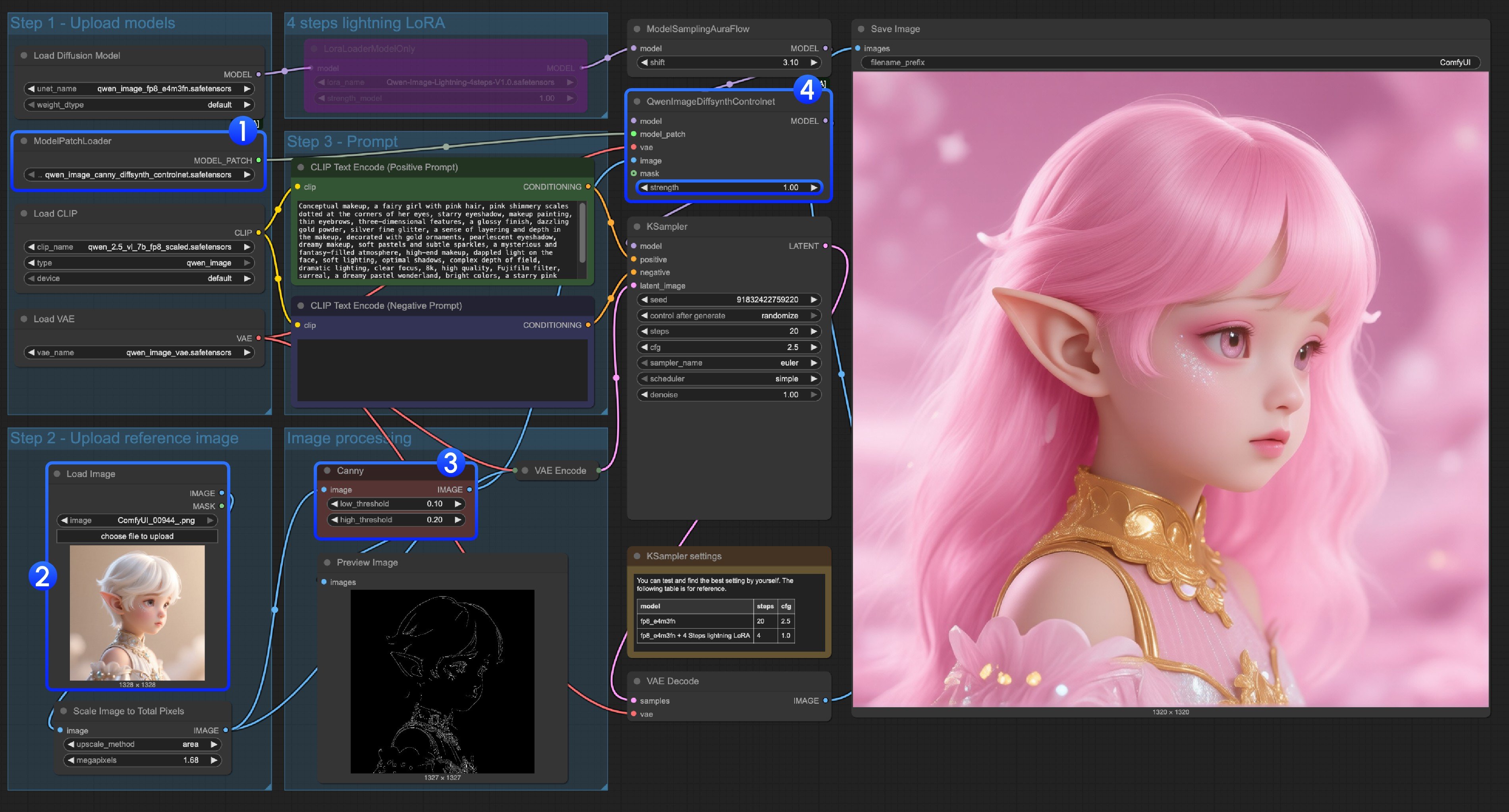
- Ensure that
qwen_image_canny_diffsynth_controlnet.safetensorsis loaded - Upload input image for subsequent processing
- The Canny node is a native preprocessing node that will preprocess the input image according to your set parameters to control generation
- If needed, you can modify the
strengthin theQwenImageDiffsynthControlnetnode to control the intensity of line art control - Click the
Runbutton, or use the shortcutCtrl(cmd) + Enterto run the workflow
For using qwen_image_depth_diffsynth_controlnet.safetensors, you need to preprocess the image into a depth map and replace the image processing part. For this usage, please refer to the InstantX processing method in this document. Other parts are similar to using the Canny model.
Inpaint Model ControlNet Usage Instructions
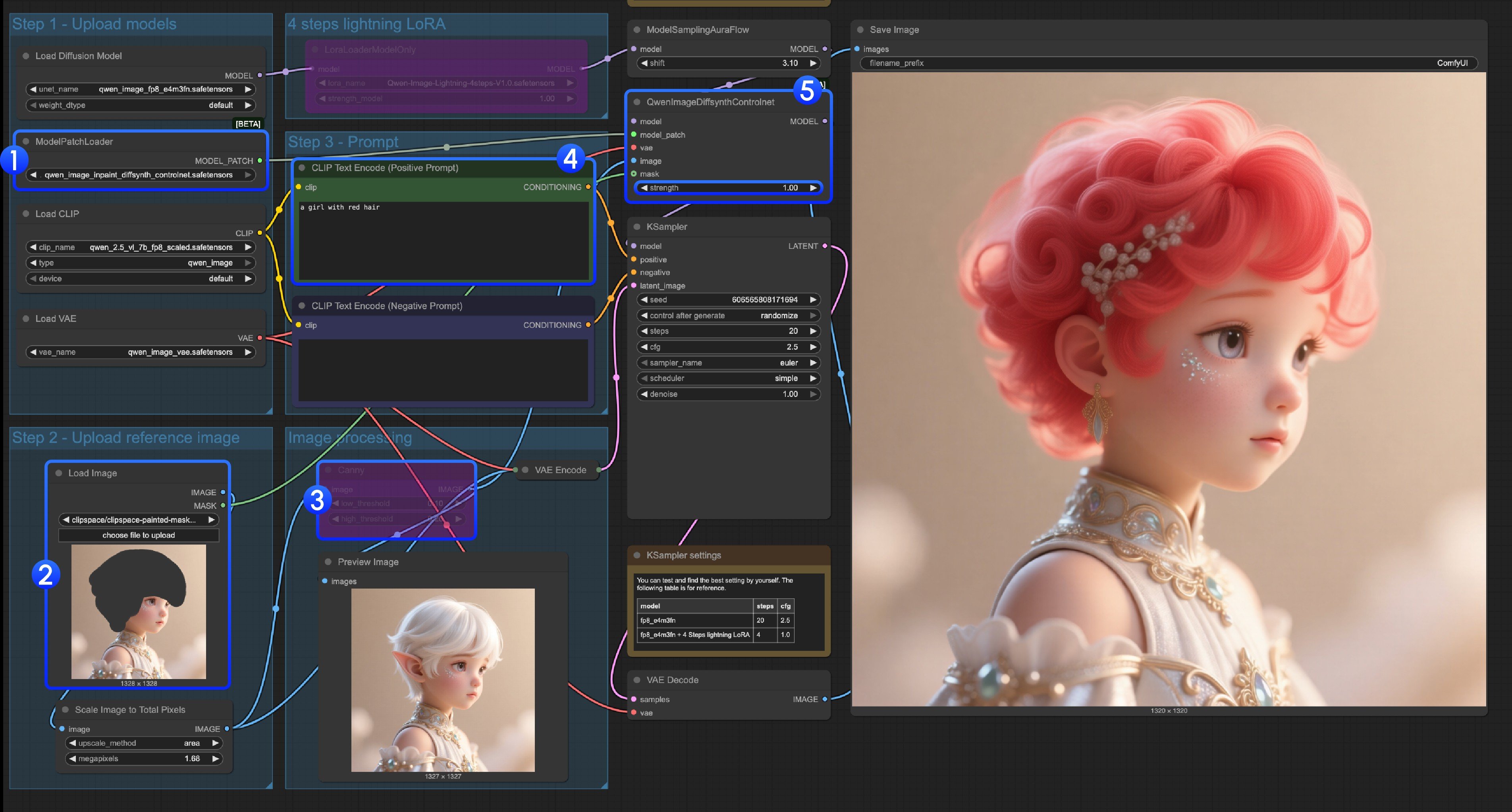
- Ensure that
ModelPatchLoaderloads theqwen_image_inpaint_diffsynth_controlnet.safetensorsmodel - Upload image and use the Mask Editor to draw a mask. You need to connect the
maskoutput of the correspondingLoad Imagenode to themaskinput ofQwenImageDiffsynthControlnetto ensure the corresponding mask is loaded - Use the
Ctrl-Bshortcut to set the original Canny in the workflow to bypass mode, making the corresponding Canny node processing ineffective - In
CLIP Text Encoder, input what you want to change the masked area to - If needed, you can modify the
strengthin theQwenImageDiffsynthControlnetnode to control the corresponding control intensity - Click the
Runbutton, or use the shortcutCtrl(cmd) + Enterto run the workflow
Qwen Image Union ControlNet LoRA Workflow
Run on Comfy Cloud Original model address: DiffSynth-Studio/Qwen-Image-In-Context-Control-Union Comfy Org rehost address: qwen_image_union_diffsynth_lora.safetensors: Image structure control LoRA supporting canny, depth, pose, lineart, softedge, normal, openpose1. Workflow and Input Images
Download the image below and drag it into ComfyUI to load the workflow
Download JSON Format Workflow
Download the image below as input
2. Model Links
Download the model below. Since this is a LoRA model, it needs to be saved to theComfyUI/models/loras/ folder
- qwen_image_union_diffsynth_lora.safetensors: Image structure control LoRA supporting canny, depth, pose, lineart, softedge, normal, openpose
3. Workflow Instructions
This model is a unified control LoRA that supports canny, depth, pose, lineart, softedge, normal, openpose controls. Since many image preprocessing native nodes are not fully supported, you should use something like comfyui_controlnet_aux to complete other image preprocessing.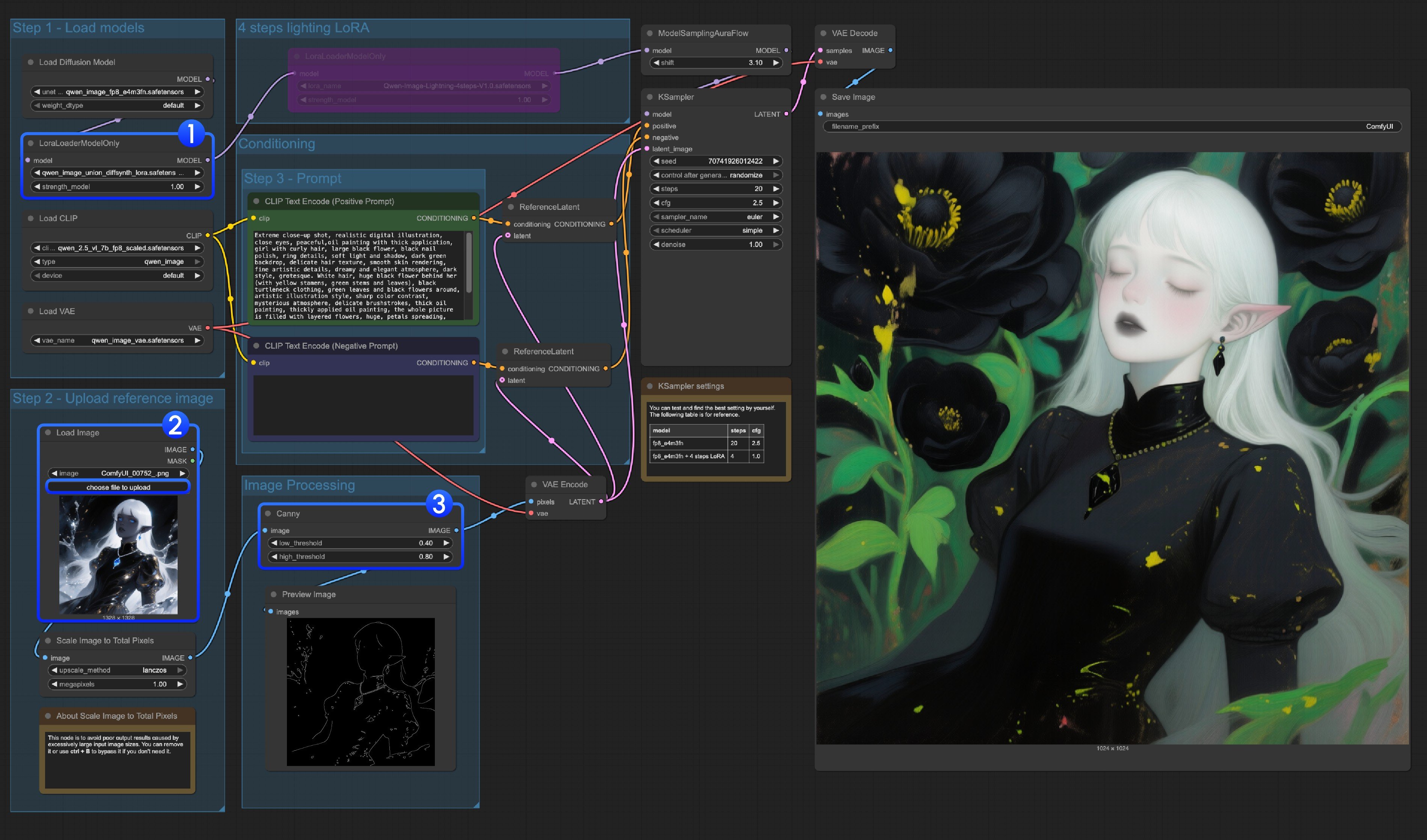
- Ensure that
LoraLoaderModelOnlycorrectly loads theqwen_image_union_diffsynth_lora.safetensorsmodel - Upload input image
- If needed, you can adjust the
Cannynode parameters. Since different input images require different parameter settings to get better image preprocessing results, you can try adjusting the corresponding parameter values to get more/fewer details - Click the
Runbutton, or use the shortcutCtrl(cmd) + Enterto run the workflow
For other types of control, you also need to replace the image processing part.